Das (physikalische) Internet
Physikalisch besteht das Internet im Kernbereich, also bei Verbindungen zwischen den oben genannten Netzwerken und in den Backbones großer Netzwerke, kontinental und interkontinental hauptsächlich aus Glasfaserkabeln, die durch Router zu einem Netz verbunden sind. Glasfaserkabel bieten eine enorme Übertragungskapazität und wurden vor einigen Jahren zahlreich sowohl als Land- als auch als Seekabel in Erwartung sehr großen Datenverkehr-Wachstums verlegt. Auch Satelliten und Richtfunkstrecken sind in die globale Internet-Struktur eingebunden, haben jedoch einen geringen Anteil. Auf der sogenannten letzten Meile, also bei den Hausanschlüssen, werden die Daten oft auf Kupferleitungen von Telefon- oder Fernsehanschlüssen und vermehrt auch über Funk, mittels WLAN oder UMTS, übertragen. Glasfasern bis zum Haus (FTTH) sind in Deutschland noch nicht sehr weit verbreitet. Privatpersonen greifen auf das Internet über einen Breitbandzugang, zum Beispiel mit DSL, Kabelmodem oder UMTS, eines Internetproviders zu.
Client In privaten Haushalten werden oft Computer zum Abrufen von Diensten ans Internet angeschlossen, die selbst wenige oder keine solche Dienste für andere Teilnehmer bereitstellen und nicht dauerhaft erreichbar sind. Solche Rechner werden als Client-Rechner bezeichnet.
Server dagegen sind Rechner, die in erster Linie Internetdienste anbieten. Sie stehen meistens in sogenannten Rechenzentren, sind dort schnell angebunden und in klimatisierten Räumlichkeiten gegen Strom- und Netzwerkausfall sowie Einbruch und Brand gesichert.
Peer-to-Peer-Anwendungen versetzen auch obige Client-Rechner in die Lage, zeitweilig selbst Dienste anzubieten, die sie bei anderen Rechnern dieses Verbunds abrufen. So wird hier die strenge Unterscheidung des Client-Server-Modells aufgelöst.
Das OSI-Referenzmodell der Netzwerkübertragung
| OSI-Schicht | Einordnung | DoD-Schicht | Einordnung | Protokollbeispiel | Einheiten | Kopplungselemente | |
|---|---|---|---|---|---|---|---|
| 7 | Anwendungen (Application) |
Anwendungs- orientiert |
Anwendung | Ende zu Ende (Multihop) |
HTTP FTP HTTPS SMTP XMPP MQTT LDAP NCP |
Daten | Gateway, Content-Switch, Proxy, Layer-4-7-Switch |
| 6 | Darstellung (Presentation) |
||||||
| 5 | Sitzung (Session) |
||||||
| 4 | Transport (Transport) |
Transport- orientiert |
Transport | TCP UDP SCTP SPX | TCP = Segmente|||
| 3 | Vermittlung-/Paket (Network) |
Internet | ICMP IGMP IP IPsec |
Pakete | Router, Layer-3-Switch | ||
| 2 | Sicherung (Data Link) |
Netzzugriff |
Punkt zu Punkt |
Ethernet Token Ring FDDI MAC< ARCNET |
Rahmen (Frames) | Bridge, Layer-2-Switch | |
| 1 | Bitübertragung (Physical) |
Bits, Symbole, Pakete | Netzwerkkabel, Repeater, Hub | ||||
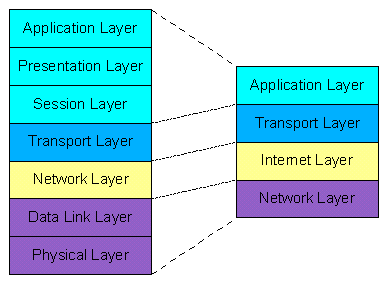
Das TCP/IP-Referenzmodell
Im vorhergehenden Abschnitt wurde das OSI-Referenzmodell vorgestellt. In diesem Abschnitt soll nun das Referenzmodell für die TCP/IP-Architektur vorgestellt werden. Das TCP/IP-Referenzmodell - benannt nach den beiden primären Protokollen TCP und IP der Netzarchitektur beruht auf den Vorschlägen, die bei der Fortentwicklung des ARPANETs gemacht wurden. Das TCP/IP-Modell ist zeitlich vor dem OSI-Referenzmodell entstanden, deshalb sind auch die Erfahrungen des TCP/IP-Modells mit in die OSI-Standardisierung eingeflossen. Das TCP/IP-Referenzmodell besteht im Gegensatz zum OSI-Modell aus nur vier Schichten: Application Layer, Transport Layer, Internet Layer, Network Layer. Als Ziele der Architektur wurden bei der Entwicklung definiert:
- Unabhängigkeit von der verwendeten Netzwerk-Technologie.
- Unabhängigkeit von der Architektur der Hostrechner.
- Universelle Verbindungsmöglichkeiten im gesamten Netzwerk.
- Ende-zu-Ende-Quittungen.
- Standardisierte Anwendungsprotokolle.
Applikationsschicht (application layer): Die Applikationsschicht (auch Verarbeitungsschicht genannt) umfaßt alle höherschichtigen Protokolle des TCP/IP-Modells. Zu den ersten Protokollen der Verarbeitungsschicht zählen TELNET (für virtuelle Terminals), FTP (Dateitransfer) und SMTP (zur Übertragung von E-Mail). Im Laufe der Zeit kamen zu den etablierten Protokollen viele weitere Protokolle wie z.B. DNS (Domain Name Service) und HTTP (Hypertext Transfer Protocol) hinzu.
Transportschicht (transport layer): Wie im OSI-Modell ermöglicht die Transportschicht die Kommunikation zwischen den Quell- und Zielhosts. Im TCP/IP-Referenzmodell wurden auf dieser Schicht zwei Ende-zu-Ende-Protokolle definiert: das Transmission Control Protocol (TCP) und das User Datagram Protocol (UDP). TCP ist ein zuverlässiges verbindungsorientiertes Protokoll, durch das ein Bytestrom fehlerfrei einen anderen Rechner im Internet übermittelt werden kann. UDP ist ein unzuverlässiges verbindungsloses Protokoll, das vorwiegend für Abfragen und Anwendungen in Client/Server-Umgebungen verwendet wird, in denen es in erster Linie nicht um eine sehr genaue, sondern schnelle Datenübermittlung geht (z.B. Übertragung von Sprache und Bildsignalen).
Internetschicht (internet layer): Die Internetschicht im TCP/IP-Modell definiert nur ein Protokoll namens IP (Internet Protocol), das alle am Netzwerk beteiligten Rechner verstehen können. Die Internetschicht hat die Aufgabe IP-Pakete richtig zuzustellen. Dabei spielt das Routing der Pakete eine wichtige Rolle. Das Internet Control Message Protocol (ICMP) ist fester Bestandteil jeder IP-Implementierung und dient zur Übertragung von Diagnose- und Fehlerinformationen für das Internet Protocol.
Netzwerkschicht (network layer): Unterhalb der Internetschicht befindet sich im TCP/IP-Modell eine große Definitionslücke. Das Referenzmodell sagt auf dieser Ebene nicht viel darüber aus, was hier passieren soll. Festgelegt ist lediglich, daß zur Übermittlung von IP-Paketen ein Host über ein bestimmtes Protokoll an ein Netz angeschlossen werden muß. Dieses Protokoll ist im TCP/IP-Modell nicht weiter definiert und weicht von Netz zu Netz und Host zu Host ab. Das TCP/IP-Modell macht an dieser Stelle vielmehr Gebrauch von bereits vorhandenen Protokollen, wie z.B. Ethernet (IEEE 802.3), Serial Line IP (SLIP), etc.
Der Weg ins Internet - Adressierung
Zugang zum Internet
Jeder Rechner, der am Internet teilnehmen will muss eine eigene, eindeutige IP-Adresse besitzen. Folgende Fälle sind möglich:
Feste IP-Adresse Dem Rechner ist eine feste IP-Adresse zugeordnet. Vorteil: Der Rechner kann immer unter derselben Adresse erreicht werden. Nachteil: IP-Adressen sind knapp, daher kann nicht grundsätzlich jeder Rechner eine eigene IP-Adresse bekommen!
Dynamische IP-Adresse Bei jeder Einwahl bekommt der Rechner vom Provider eine neue IP-Adresse zugeteilt. Vorteil: Nur der Provider muss über genügend viele IP-Adressen verfügen. Diese Anzahl ist kleiner als alle Rechner, die dem Provider zugeordnet sind, da nicht immer alle Rechner gerade eingewählt sind. Nachteil: Ein Rechner ist nicht mehr eindeutig identifizierbar, was ungeeignet ist für Webserver usw.
Adresstranslation (NAT) Die Rechner im lokalen Netzwerk haben nicht öffentliche IP-Adressen. Sie gehen über einen Proxyserver ins Internet. Der Proxyserver gibt die Anfrage unter seiner eigenen öffentlichen IP-Adresse weiter und leitet die eingehende Antwort wieder an den anfragenden Rechner weiter. Vorteil: Es wird nur eine öffentliche IP-Adresse für den Proxyserver benötigt. Die Rechner im lokalen Netz sind von außen „unsichtbar“.
Wenn ein Rechner ans Internet angeschlossen ist, so ist er als Teil des weltweiten Internet aktiv und kann entsprechend von überall her über seine IP-Adresse angesprochen werden.
Routing im Internet
Wie finden die Datenpakete im Internet ihren Weg? Im Internet sind viele Netzwerke miteinander verbunden.
Datenpakete werden innerhalb eines Netzwerks direkt zum Zielrechner geschickt. Details. Liegt der Zielrechner außerhalb des eigenen Netzwerks, so muss es über einen sogenannten Router weitergeleitet werden. Der Rechner sendet das IP-Paket für den fremden Zielrechner an den Router. Liegt das Ziel in einem Netz, auf das der Router direkten Zugriff hat, so stellt er das Datenpaket direkt zu. Andernfalls übergibt er es an den nächsten geeigneten Router. Details. Verfolgung von Routen mit Traceroute
Mit Traceroute können Routen im Internet protokolliert und damit verfolgt werden.

Die Anweisung in der Windows Commandozeile (Ausführen → CMD) lautet: tracert <Zieladresse>.
Domain Name System
Da es den meisten Mensch schwer fällt, sich IP-Adressen zu merken, wurde im Internet von vornherein die Möglichkeit vorgesehen, Rechner zusätzlich zu den IP-Adressen auch noch mit frei wählbaren logischen Namen zu versehen. Diese Zuordnung kann über eine sog. Hosts-Tabelle erfolgen. In dieser Tabelle wird, ähnlich einem Telefonbuch, jedem Rechner eine eindeutige IP-Adresse und ein logischer Name zugewiesen. Wird das Netzwerk um einen Rechner erweitert, so muss die Hosts-Tabelle angepasst werden. Im Internet war die Verwaltung von Rechnernamen und IP-Adressen in Tabellen bis 1984 die einzig benutzte Methode. Dabei wurden die Rechneradressen und Namen des gesamten Internet in den USA von einer einzigen Stelle, dem NIC (Network Information Center), zentral verwaltet. Diese Tabelle wurde regelmäßig an die Server im Internet verteilt. Als das Internet allerdings immer stärker anwuchs, wurde der organisatorische Aufwand zu groß. Mit dem Domain Name System (DNS) wurde ein neues Verfahren zur Adressierung von Rechnernamen eingeführt. Aufbau und Struktur des DNS
Das Domain Name System ist in einer Baumstruktur organisiert. Nach der Wurzel (Root) folgt als oberste Ebene die Ebene der Top-Level-Domains. Dann kommt die Ebene der First-Level-Domain. Weitere Ebenen (Subdomains) können folgen. Unter einer Domain versteht man die Ansammlung von Rechnern, die nach organisatorischen oder geographischen Gesichtspunkten zusammengehören. Die Abbildung zeigt eine solche Struktur am Beispiel von Wikipedia.
 Quelle: Wikipedia
Quelle: Wikipedia
URL: Uniform Resource Locator Jede Web-Seite besitzt eine eindeutige URL. Der Aufbau einer URL ist nachfolgend beschrieben:
|------------------ Schema-spezifischer Teil (Vollständig)------------------|
https://max:muster@www.example.com:8080/index.html?p1=A&p2=B#ressource
\___/ \_/ \____/ \_____________/ \__/\_________/ \_______/ \_______/
| | | | | | | |
Schema⁺ | Kennwort Host Port Pfad Query Fragment
Benutzer
|------------------ Schema-spezifischer Teil (Üblich am beispiel Schule)------------------|
http://ticket.mso-hef.de
\___/ \__/ \________/
| | |
Protokoll | Host
Subdomain
Wenn ein Client einen logischen Namen für einen Computer im Internet verwendet (z. B. www.lbs.bw.schule.de), wird zunächst eine Anfrage an einen DNS-Server (Nameserver) gestellt. In der Regel geht die Anfrage an den DNS-Server des Providers. Am Client wird die IP-Adresse des DNS-Servers bei den Eigenschaften von TCP/IP in der Netzwerkumgebung eingestellt.
Falls dem DNS-Server die gewünschte Adresse bekannt ist, so gibt der Nameserver die Adresse direkt an den Client zurück. Dieser kann nun eine TCT/IP-Verbindung zum Webserver mit der nun bekannten IP-Adresse aufbauen und eine HTTP-Anfrage mit der gewünschten URL an den Webserver richten.
Bei der Anzahl der Server im Internet ist es unmöglich, dass ein Nameserver alle Adressen kennt. Die Namensauflösung (Resolving) wird deshalb von einem Verbund von Nameservern übernommen, die entsprechend der Ebenen im Domain-Name-System angeordnet sind. An der Spitze stehen die sogenannten Root-Nameserver. Sie kennen die Nameserver aller Top-Level-Domains. Die Nameserver der Top-Level-Domains kennen wiederum die Nameserver der ihnen untergeordneten First-Level-Domains usw.
Wenn der zuerst angesprochene Nameserver die Adresse nicht kennt, so befragt er in der Regel einen Root-Nameserver. Dieser nennt ihm einen Nameserver für die Top-Level-Domain, die im DNS-Name der URL angegeben ist. Der vom Client befragte Nameserver befragt anschliessend diesen Nameserver und bekommt eventuell einen Verweis auf Nameserver von Subdomains, bis er einen Nameserver findet, der die Anfrage beantworten kann. Nun endlich kann er die gewünschte Adresse an den Client zurück liefern.
Neben den primären Nameservern für die jeweilige Zone gibt es aus Gründen der Ausfallsicherheit immer auch sekundäre Nameserver. Diese beziehen eine Nur-Lese-Kopie der Adressdatenbank von ihrem primären Nameserver. Bei der Namensauflösung bekommt ein Nameserver mehrere Vorschläge von Nameservern, die er als nächste befragen kann. Er wählt mehr oder weniger zufällig einen davon aus. Dies führt zu einer Lastverteilung zwischen den Nameservern.
Um die Zahl der DNS-Anfragen zu vermindern merken sich Nameserver die einmal ermittelten Adressen für eine gewisse Zeit. Dieser Vorgang wird als Caching bezeichnet. Es gibt auch sogenannte Caching-Only-Nameserver, die selbst keine eigene Adressdatenbank führen. Da Nameserver die Adresse der ihnen übergeordneten Nameserver kennen, ist es auch möglich, dass ein Nameserver seinen übergeordneten Nameserver befragt und so weiter. Spätestens bei einer Anfrage nach einer Adresse aus einer anderen Top-Level-Domain muss die Adressauflösung wie oben beschrieben über einen Root-Nameserver erfolgen.
Rootserver Die Wurzel des hierarchischen DNS-Namensraumes bilden so genannte Rootserver. Die gesamte DNS beruht auf 13 geografisch verteilten Root-Nameservern. Sie werden mit A.ROOT-SERVER, B.ROOT-SERVER usw. bezeichnet. Die eigentliche Wurzel des gesamten Systems bildet eine einzige Datei, das Root-Zonen-File. Diese Datei und der zentrale A.ROOT-SERVER wird derzeit von Network Solutions verwaltet. Auf den Rootservern B bis M befinden sich Kopien des Root-Zonen-Files.
Jeder Nameserver im Internet kennt in der Regel alle 13 Root-Nameserver.